先日、さくらインターネットさんの大阪本社にお伺いして、インタビューを受けました。
詳しくは、さくらのナレッジをご覧ください!
C#をもぐもぐしているblog
ご無沙汰しています!数年ぶりのblog更新ですが、生きております。
今回の記事ですが、数年ぶりにTerraformで管理していたCloudflareのメンテナンスをするべく、terraform planを実行したところ、どうやら化石となってしまったtfstateファイルの中身が原因で実行できないという事態が発生しました。
また、Terraformの設定内容を記載しているtfファイル自身も書き方が色々と変わっていたらしく、備忘録に書き残せればと思います。
| 作業OS | Windows 11 Pro Ver.21H2 Build.22000.856 |
| Terraform | v1.2.8 on windows_amd64 |
| 前回メンテ日 | 2018/10/21 |
| 今回メンテ日 | 2022/9/1 |
| ソースコード | https://github.com/223n/223nTech |
tfファイルの先頭にterraformを追加しました。
どうやら、バージョンアップでおまじないになっている様子…
0.13で何があったんや…
コード1. terraformの追加
terraform {
required_version = ">= 0.13"
required_providers {
cloudflare = {
source = "cloudflare/cloudflare"
}
}
} 従来は、環境変数に「CLOUDFLARE_EMAIL」と「CLOUDFLARE_TOKEN」を定義しておけばよかったのですが、どうもそれではダメになった様子…
tfファイルでは、tfファイル内で使用する変数を定義しておき、環境変数に設定値を設定するようにしました。
コード2. 変数を定義
# Cloudflareで使用しているメールアドレス
variable "CLOUDFLARE_EMAIL" {
type = string
}
# Cloudflareで取得したGlobal API
variable "CLOUDFLARE_TOKEN" {
type = string
sensitive = true
}
# 設定対象のゾーンID
variable "CLOUDFLARE_ZONE_ID" {
type = string
}tfファイルで定義した変数に環境変数の設定値を反映させるためには、変数名の頭に「TF_VAR_」と付けておく必要があるので、要注意です。

変数定義の下に、providerを追加しました。
ここでは、Cloudflareの接続に必要なメールアドレスとAPIを割り当てています。
コード3. providerの追加
provider "cloudflare" {
email = var.CLOUDFLARE_EMAIL
api_key = var.CLOUDFLARE_TOKEN
}あとは、ひたすらフォーマットを変えていきます。
コード4. 変更例(変更前後)
resource cloudflare_page_rule "223n_tech_rule" {
"zone" = "223n.tech"
"target" = "blog.223n.tech/*"
"priority" = 1
"actions" = {
"ssl" = "strict"
"always_use_https" = true
}
}resource "cloudflare_page_rule" "_223n_tech_rule" {
zone_id = var.CLOUDFLARE_ZONE_ID
target = "blog.223n.tech/*"
priority = 1
actions {
ssl = "strict"
always_use_https = true
}
} この事例では、resourceの次にそのまま「cloudflare_page_rule」といった種類を書いていたのですが、””で括っています。
また、一意の識別名が従来数字から始まっても良かったのですが、英字もしくは_で始めなければならないとのことらしいので、すべての識別名に「_」を追加しています。
コード5. 種類に""を追加と識別名を英字もしくは_で開始するように変更(変更前後)
resource cloudflare_page_rule "223n_tech_rule" {resource "cloudflare_page_rule" "_223n_tech_rule" {その代わり、従来は「zone」や「target」などを””で括っていましたが、””を削除しています。
コード6. 変数名の""を削除(変更前後)
"target" = "blog.223n.tech/*" target = "blog.223n.tech/*" 次に、従来は「zone」で設定対象のドメイン名を設定していたところは、「zone_id」となり、Cloudflareで取得したゾーンIDを設定してあげる必要が発生しました。
ここで、先ほど定義した変数「CLOUDFLARE_ZONE_ID」を使用しています。
コード7. zoneからzone_idに変更対応(変更前後)
"zone" = "223n.tech" zone_id = var.CLOUDFLARE_ZONE_IDまた、「actions」などの変数に複数の変数を定義しているようなものは、=でつながない書き方に変わっています。
コード8. 複数の変数を子持ちする変数の書き方変更対応(変更前後)
"actions" = {
"ssl" = "strict"
"always_use_https" = true
} actions {
ssl = "strict"
always_use_https = true
} tfstateファイルは、Terraformで設定した内容を保持してくれているファイルで、このファイルがあることで、現状のCloudflareの設定内容とtfファイルで定義している設定内容を比較することで、「terraform plan」などを実行した際に結果予想などを表示してくれる重要なファイルです。
しかし、残念ながら今のtfファイルではv0.13の壁を超える手段がなく、この後、tfファイルを再作成するため、バッサリと削除してしまいます。
Terraformでは、tfファイルで設定した内容と実際の設定内容を紐づけてtfstateファイルに記録してくれる「import」という機能があります。
しかし、「import」を実行するためには、それぞれの設定項目ごとにCloudflareで持っている設定ごとの「ID」が必要となるため、今回はcurlコマンドで取得をします。
コード9. ページルールを取得するcurlコマンド
curl -X GET "https://api.cloudflare.com/client/v4/zones/##ゾーンID##/pagerules" -H "X-Auth-Email: ##メールアドレス##" -H "X-Auth-Key: ##Global API##" -H "Content-Type: application/json"
(注記)コマンド内の##xxxx##の箇所は、下表の値を置き換えてから実行してください。
| ##ゾーンID## | 設定対象のゾーンID 環境変数の「TF_VAR_CLOUDFLARE_ZONE_ID」に設定した内容 |
| ##メールアドレス## | Cloudflareで使用しているメールアドレス 環境変数の「TF_VAR_CLOUDFLARE_TOKEN」に設定した内容 |
| ##Global API## | Cloudflareで取得したGlobal API 環境変数の「TF_VAR_CLOUDFLARE_ZONE_ID」に設定した内容 |
実行して正常にデータが取得できると、json形式でデータが返ってきます。
Visual Studio Codeなどにjsonファイルとして保存しておき、「ドキュメントのフォーマット」で見やすいように整形してあげてください。
以下のような内容が取得できるかと思います。
実行結果1. ページルールの取得結果
{
"result": [
{
"id": "##このページルールの固有ID##",
"targets": [
{
"target": "url",
"constraint": {
"operator": "matches",
"value": "blog.223n.tech\/*"
}
}
],
"actions": [
{
"id": "ssl",
"value": "strict"
},
{
"id": "always_use_https"
}
],
"priority": 1,
"status": "active",
"created_on": "2018-04-15T07:00:33.000000Z",
"modified_on": "2019-07-04T18:44:00.000000Z"
}
],
"success": true,
"errors": [],
"messages": []
} 今回、ページルールは1個しか定義していないため、result内の最初に出てくる「ID」が欲しい情報ですので、メモしておきます。
ここでは、「##このページルールの固有ID##」と書かれている場所に、英数字が記載されています。
先ほどの手順で必要な情報は揃いましたので、ページルールのimportを実行します。
基本的な構文は、以下のようになっています。
なお、「##紐づけたい種類##」と「##紐づけたい識別名##」の間は「.」がありますので、忘れないようにしてください。
コード10. importコマンド構文
terraform import ##紐づけたい種類##.##紐づけたい識別名## ##ゾーンID##/##取得したID##| ##紐づけたい種類## | tfファイルでresourceの次に書いている種類 |
| ##紐づけたい識別名## | tfファイルでresourceの種類の次に書いている一意の識別名 |
| ##ゾーンID## | 設定対象のゾーンID 環境変数の「TF_VAR_CLOUDFLARE_ZONE_ID」に設定した内容 |
| ##取得したID## | 「実行結果1.」などで取得した「##ページルールのID##」といったID |
例えば、今回は以下のような設定に対して取得するので、コマンドは以下のようになります。
コード11. ページルールの設定(tfファイル)
resource "cloudflare_page_rule" "_223n_tech_rule" {
zone_id = var.CLOUDFLARE_ZONE_ID
target = "blog.223n.tech/*"
priority = 1
actions {
ssl = "strict"
always_use_https = true
}
}コード12. importコマンド(コード11の設定と紐づける場合)
terraform import cloudflare_page_rule._223n_tech_rule ##ゾーンID##/##ページルールのID##無事に取り込みが完了すると、「Import successful!」といった結果が表示されます。

もし、1回実行していて変更点が無い場合には、「Error: Resource already managed by Terraform」といったエラー結果が表示されます。

あとは、DNSレコードを同じようにリストで取得してCloudflareで割り当てられているIDを取得、importコマンドをひたすら実行する流れです。
コード13. DNSレコードを取得するcurlコマンド
curl -X GET "https://api.cloudflare.com/client/v4/zones/##ゾーンID##/dns_records" -H "X-Auth-Email: ##メールアドレス##" -H "X-Auth-Key: ##Global API##" -H "Content-Type: application/json"
(注記)コマンド内の##xxxx##の箇所は、下表の値を置き換えてから実行してください。
| ##ゾーンID## | 設定対象のゾーンID 環境変数の「TF_VAR_CLOUDFLARE_ZONE_ID」に設定した内容 |
| ##メールアドレス## | Cloudflareで使用しているメールアドレス 環境変数の「TF_VAR_CLOUDFLARE_TOKEN」に設定した内容 |
| ##Global API## | Cloudflareで取得したGlobal API 環境変数の「TF_VAR_CLOUDFLARE_ZONE_ID」に設定した内容 |
ページルールと同様に実行して正常にデータが取得できると、json形式でデータが返ってきます。
Visual Studio Codeなどにjsonファイルとして保存しておき、「ドキュメントのフォーマット」で見やすいように整形してあげてください。
以下のような内容が取得できるかと思います。
実行結果2. DNSレコードの取得結果(一部中略)
{
"result": [
{
"id": "##このDNSレコードのID##",
"zone_id": "##ゾーンID##",
"zone_name": "223n.tech",
"name": "223n.tech",
"type": "CAA",
"content": "0 issue \"letsencrypt.org\"",
"proxiable": false,
"proxied": false,
"ttl": 1,
"locked": false,
"data": {
"flags": 0,
"tag": "issue",
"value": "letsencrypt.org"
},
"meta": {
"auto_added": false,
"managed_by_apps": false,
"managed_by_argo_tunnel": false,
"source": "primary"
},
"created_on": "2022-09-01T06:59:09.329106Z",
"modified_on": "2022-09-01T06:59:09.329106Z"
},
## 中略 ##
{
"id": "##このDNSレコードのID##",
"zone_id": "##ゾーンID##",
"zone_name": "223n.tech",
"name": "blog.223n.tech",
"type": "NS",
"content": "ns1.dns.ne.jp",
"proxiable": false,
"proxied": false,
"ttl": 1,
"locked": false,
"meta": {
"auto_added": false,
"managed_by_apps": false,
"managed_by_argo_tunnel": false,
"source": "primary"
},
"created_on": "2019-07-04T18:44:01.881493Z",
"modified_on": "2019-07-04T18:44:01.881493Z"
},
## 中略 ##
],
"success": true,
"errors": [],
"messages": [],
"result_info": {
"page": 1,
"per_page": 100,
"count": 17,
"total_count": 17,
"total_pages": 1
}
} あまりにも結果が長いので、一部中略していますが、DNSレコードごとに括られた状態で整形されると思います。
あとは、tfファイルで設定している内容から該当するDNSレコードを探し、「”id”」の「##このDNSレコードのID##」の箇所に記載されているIDをメモしていきます。
import構文は重複するので作業内容7.をご参照いただくとして、例えば、今回は以下のような設定に対して取得するので、コマンドは以下のようになります。
コード14. ページルールの設定(tfファイル)
resource "cloudflare_record" "_223n_tech_issuewild" {
zone_id = var.CLOUDFLARE_ZONE_ID
type = "CAA"
name = "@"
data {
flags = "0"
tag = "issuewild"
value = "letsencrypt.org"
}
}コード15. importコマンド(コード14の設定と紐づける場合)
terraform import cloudflare_record._223n_tech_issuewild ##ゾーンID##/##DNSレコードのID## ここまでくれば、あとは、planを実行して試すのみです!
もし、planを実行した後にapplyを実行して「tfstateの状態と実際の状態が異なる」といったエラーが発生した場合には、該当のtfファイルの設定に紐づくimportコマンドを再実行してからplan、applyを実行してみてください。

かなり手間取りましたが、そりゃあ数年放置したソースがそのまま使えるわけがないですよね…
Wordpressに関しては、すべて自動的にアップデートが実行されるように組んであるので問題はないのですが、Terraformなどの構築設定後に触ることのないものは、要注意ですね…
このブログを含めていくつかWordpressのサイトをさくらのレンタルサーバで構築しているのですが、さくらインターネットさんの方でバックアップの機能が用意されています。
バックアップにはSnapUpを使用しており、CMSではWordpressのバックアップに対応しています。
そこで、手順に従ってバックアップを作成しようと試みたのですが、なぜかエラーになってしまいました。
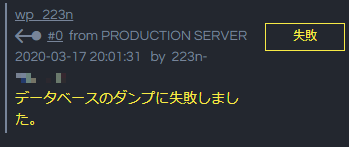
調べてみても原因が分からず、さくらインターネットに問い合わせたところ、原因は「.my.cnf」にありました。
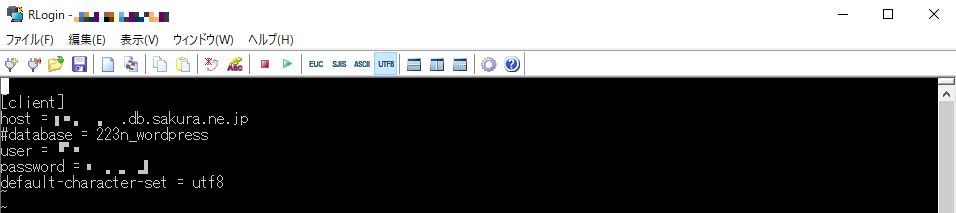
どうやら、SnapUpのデータベースのダンプには、「mysqldump」コマンドが使用されているとのことで、「.my.cnf」ファイルに「database = xxx」という行があるため、ダンプに失敗してしまったようです。
画像のように最初に「#」を付けてコメントアウトしてあげることで、正常にバックアップを作成することができました!
(ありがとう、さくらインターネットさん!)

お久しぶりです。生きていた223nです。
昨年から一緒に仲間とイベントをやってみたり、個人的に考えたりすることが増えました。
そのため、少しだけ今考えていることをまとめました。
三河INGRESSイベント実行委員会の仲間に協力してもらいながら企画、準備、実施としてきました。
ほとんどが役所や観光協会などとのやりとりでしたが、初めての体験で楽しんでいました。
ただ、どんどんやることを増やすと体力の消耗が激しくなります。
なので2回目以降は体力が持つようにセーブしてやっています。
こちらは企画段階です。
まだ⬜️⬜️⬜️から連絡がないので開催できるか全くわかりませんが、開催できると良いな〜
こちらもまだ企画段階です。
MDなどとの同時開催ではなく、単発でやりたいなと。
フォックスハントなどといったINGRESSを使って指定されたエージェントやアイテムを探すなどのイベントを考えています。
あとは運動会みたいなのも良いなぁとも…
これもできたらいいなぁ。
弐寺。
おうちで毎日2時間BMSをやれば皆伝楽勝という皆伝保持者の自伝から、個人的にやってみようと思います。
ちなみに音ゲーはリフレクビートをメインにやっていたので、他の音ゲーはからっきしです。
そのため、ノーマルもまだクリアできたりできなかったり…
(二個押しの連続とかが降ってくると混乱してます)
これを機にYouTubeでライブで記録を残しながらやってみるのもありかなぁとも思ってます。
ちなみに、おうちではbeatorajaを使う予定です。
わたし…働きたい…